
Les posteurs les plus actifs de la semaine
| Aucun utilisateur |
Sujets les plus vus
Interprétation des résultats Modèles Linéaires Généralisés
2 participants
Page 1 sur 1

Interprétation des résultats Modèles Linéaires Généralisés
par Yak Dim 18 Oct 2015 - 12:29
Bonjour,
Je suis complètement débutant dans le fabuleux monde des stats, et j'ai pas mal de difficultés à comprendre comment interpréter les résultats du tableau "Estimation des paramètres" fourni par SPSS en utilisant les modèles linéaires généralisés.
Les participants de l'étude sont confrontés à deux stimuli simultanés qui peuvent être Positif, Négatif ou Neutre. Les participants indiquent ensuite leur ressenti perçu sur une échelle de Likert de 0 à 9.
D'après la représentation graphique des résultats, les stimuli comprenant un élément négatif influenceraient davantage le ressenti des participants. J'aimerais pouvoir quantifier l'influence relative de chaque composant de stimulus sur le score de ressenti des participants.
Voici les résultats :
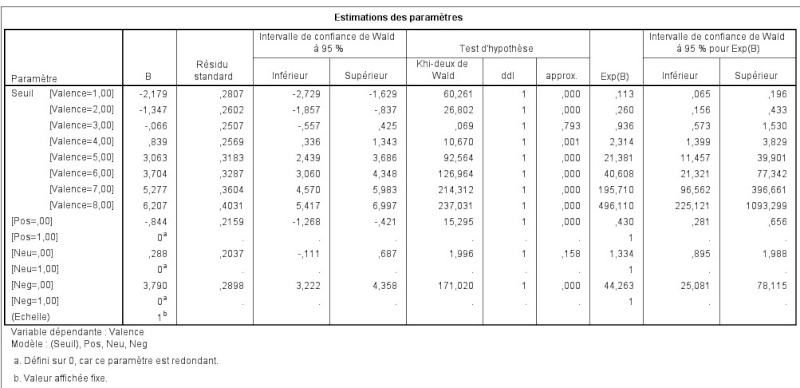
Dans la colonne Exp(B), la valeur de Neg est de 44, tandis que celle de Pos est de 0,430. Est ce que cela signifie que les stimuli négatifs auraient 44 fois plus de poids ? Et comment interpréter la valeur des stimuli positifs inférieurs à 0 ? ça ne devrait pas être plutôt le contraire puisque les valeurs de ressenti indiquées par les participants sont croissantes ? Et comment peut-on interpréter les valeurs de seuil de la colonne B ?
Merci beaucoup pour votre aide !
Je suis complètement débutant dans le fabuleux monde des stats, et j'ai pas mal de difficultés à comprendre comment interpréter les résultats du tableau "Estimation des paramètres" fourni par SPSS en utilisant les modèles linéaires généralisés.
Les participants de l'étude sont confrontés à deux stimuli simultanés qui peuvent être Positif, Négatif ou Neutre. Les participants indiquent ensuite leur ressenti perçu sur une échelle de Likert de 0 à 9.
D'après la représentation graphique des résultats, les stimuli comprenant un élément négatif influenceraient davantage le ressenti des participants. J'aimerais pouvoir quantifier l'influence relative de chaque composant de stimulus sur le score de ressenti des participants.
Voici les résultats :
Dans la colonne Exp(B), la valeur de Neg est de 44, tandis que celle de Pos est de 0,430. Est ce que cela signifie que les stimuli négatifs auraient 44 fois plus de poids ? Et comment interpréter la valeur des stimuli positifs inférieurs à 0 ? ça ne devrait pas être plutôt le contraire puisque les valeurs de ressenti indiquées par les participants sont croissantes ? Et comment peut-on interpréter les valeurs de seuil de la colonne B ?
Merci beaucoup pour votre aide !
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Eric Wajnberg Dim 18 Oct 2015 - 16:06
les paramètres négatifs ont une influence négative sur la variable modélisée. Les paramètres positifs ont une influence positive. Ceci est à relativiser à leur erreur standard (improprement appelés "résidu standard" dans les sorties que vous nous montrez), et donc à leur significativité statistique (voir les colonnes test d'hypothèse). La valeur exp(B) est juste l'exponentiel des paramètres.
Impossible d'en dire d'avantage si vous ne précisez pas de quel modèle linéaire généralisé il s'agit (il y en a de nombreux) et comment est codé la variable modélisée.
Cordialement,
Eric.
Impossible d'en dire d'avantage si vous ne précisez pas de quel modèle linéaire généralisé il s'agit (il y en a de nombreux) et comment est codé la variable modélisée.
Cordialement,
Eric.

Eric Wajnberg- Nombre de messages : 1238
Date d'inscription : 14/09/2012
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Yak Dim 18 Oct 2015 - 19:40
Bonjour Eric,
Merci pour votre réponse.
Les participants sont confrontés à des couples de stimuli, chaque stimulus pouvant prendre l'une des trois valeurs "Positif", "Négatif", "Neutre". Il y a donc 6 combinaisons possibles. Mais j'ai recodé cette variable en trois variables dichotomiques, afin de faire apparaître ces trois facteurs plutôt que les 6 combinaisons de couple.
Ainsi par exemple, le couple de stimuli "Neutre/Positif" correspond à ces trois valeurs : Positif = 1, Neutre = 1, Négatif = 0.
La variable dépendante étant ordinale, j'ai choisi une régression ordinale logistique.
Merci pour votre réponse.
Les participants sont confrontés à des couples de stimuli, chaque stimulus pouvant prendre l'une des trois valeurs "Positif", "Négatif", "Neutre". Il y a donc 6 combinaisons possibles. Mais j'ai recodé cette variable en trois variables dichotomiques, afin de faire apparaître ces trois facteurs plutôt que les 6 combinaisons de couple.
Ainsi par exemple, le couple de stimuli "Neutre/Positif" correspond à ces trois valeurs : Positif = 1, Neutre = 1, Négatif = 0.
La variable dépendante étant ordinale, j'ai choisi une régression ordinale logistique.
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Eric Wajnberg Lun 19 Oct 2015 - 5:16
Des couples de stimuli ou chacun à trois modalités, chez moi ca fait 9 combinaisons, pas 6. Ou alors chez loupé quelque chose.
Votre réponse n'est donc pas claire. Je ne comprends notamment pas ce que vous voulez dire par "cette variable". De quelle variable parlez vous?
Combien de modalités (si j'ai bien compris qualitatives, ou semi-quantitatives) a la variable dépendantes?
Peut-être devriez-vous donner un exemple de données et le code utilisé pour l'ajustement.
Eric
Votre réponse n'est donc pas claire. Je ne comprends notamment pas ce que vous voulez dire par "cette variable". De quelle variable parlez vous?
Combien de modalités (si j'ai bien compris qualitatives, ou semi-quantitatives) a la variable dépendantes?
Peut-être devriez-vous donner un exemple de données et le code utilisé pour l'ajustement.
Eric
Eric Wajnberg- Nombre de messages : 1238
Date d'inscription : 14/09/2012
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Yak Lun 19 Oct 2015 - 7:44
Bonjour,
Voici quelques précisions complémentaires.
Effectivement, si l'on tient compte de l'ordre des combinaisons, il y en a bien 9 en tout. Cependant, je ne souhaite pas tenir compte de l'ordre (les résultats pour les couples inversés sont similaires, sans différence significative).
J'ai donc mis en place le codage suivant :
Couple Positif/Positif : Positif = 1, Neutre = 0, Négatif = 0
Couple Neutre/Neutre : Positif = 0, Neutre = 1, Négatif = 0
Couple Négatif/Négatif : Positif = 0, Neutre = 0, Négatif = 1
Couple Positif/Négatif (ou inversement) : Positif = 1, Neutre = 0, Négatif = 1
Couple Positif/Neutre (ou inversement) : Positif = 1, Neutre = 1, Négatif = 0
Couple Neutre/Négatif (ou inversement) : Positif = 0, Neutre = 1, Négatif = 1
Au lieu d'avoir une variable dépendante à 6 modalités, le codage me permet de passer à trois variables dichotomiques. Cela permet de mettre en évidence l'influence des trois "effets" qui m’intéressent (je ne suis pas certain que le terme soit approprié)...
Est-ce plus clair comme ceci ?
Voici quelques précisions complémentaires.
Effectivement, si l'on tient compte de l'ordre des combinaisons, il y en a bien 9 en tout. Cependant, je ne souhaite pas tenir compte de l'ordre (les résultats pour les couples inversés sont similaires, sans différence significative).
J'ai donc mis en place le codage suivant :
Couple Positif/Positif : Positif = 1, Neutre = 0, Négatif = 0
Couple Neutre/Neutre : Positif = 0, Neutre = 1, Négatif = 0
Couple Négatif/Négatif : Positif = 0, Neutre = 0, Négatif = 1
Couple Positif/Négatif (ou inversement) : Positif = 1, Neutre = 0, Négatif = 1
Couple Positif/Neutre (ou inversement) : Positif = 1, Neutre = 1, Négatif = 0
Couple Neutre/Négatif (ou inversement) : Positif = 0, Neutre = 1, Négatif = 1
Au lieu d'avoir une variable dépendante à 6 modalités, le codage me permet de passer à trois variables dichotomiques. Cela permet de mettre en évidence l'influence des trois "effets" qui m’intéressent (je ne suis pas certain que le terme soit approprié)...
Est-ce plus clair comme ceci ?
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Eric Wajnberg Lun 19 Oct 2015 - 8:08
Oui, c'est plus clair sur le codage à présent.
Ce qui n'est toujours pas clair cependant est quelle régression logistique avez vous ajusté. Je ne crois pas - a priori - qu'il s'agisse d'une régression logistique ordinal ou non car la variable à expliquer n'est pas une variable binomiale ou multinomiale.
Il faut que l'on connaisse le modèle ajusté pour comprendre la signification des paramètres, ce qui est votre demande initiale. Peut-être que de fournir le code que vous avez envoyé pour réaliser l'ajustement aiderait, comme je l'avais déjà suggéré.
Eric.
Ce qui n'est toujours pas clair cependant est quelle régression logistique avez vous ajusté. Je ne crois pas - a priori - qu'il s'agisse d'une régression logistique ordinal ou non car la variable à expliquer n'est pas une variable binomiale ou multinomiale.
Il faut que l'on connaisse le modèle ajusté pour comprendre la signification des paramètres, ce qui est votre demande initiale. Peut-être que de fournir le code que vous avez envoyé pour réaliser l'ajustement aiderait, comme je l'avais déjà suggéré.
Eric.
Eric Wajnberg- Nombre de messages : 1238
Date d'inscription : 14/09/2012
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Yak Lun 19 Oct 2015 - 10:20
J'essaie de répondre au mieux, mais comme je suis essentiellement autodidacte, je ne maîtrise pas encore le bon vocabulaire pour bien m'expliquer (et bien vous comprendre...)
Dans SPSS, le tableau de résultats comprend cinq variables :
- la valence (variable renseignée par le participant pour chaque présentation de stimuli, et qui correspond à un score compris entre 1 à 9)
- le couple (qui correspond au stimulus présenté, et qui sert de base au codage en positif/neutre/négatif)
- la valeur de "Positif" pour le couple considéré, 0 ou 1
- la valeur de "Neutre"
- la valeur de "Négatif"
A partir de là, j'ai choisi le menu Analyse > Modèles linéaires Généralisés > Modèles linéaires Généralisés
Pour l'onglet modèle, j'ai choisi Réponse ordinale > Logistique ordinale
(parce que ma variable dépendante est ordinale)
Pour l'onglet réponse, j'ai placé la valence renseignée par l'utilisateur en tant que variable dépendante
Pour l'onglet Prédicteurs, j'ai placé les variables Positif, Neutre, et Négatif en facteurs
Pour l'onglet Modèle, j'ai également placé les variables Positif, Neutre, et Négatif en facteurs comme "effets principaux" (mais je ne sais pas à quoi correspondent les autres options, notamment "factoriel" ou "interaction")
Pour l'onglet Estimation, méthode Fischer
Pour l'onglet Statistiques, j'inclue les estimations des paramètres de la distribution exponentielle
J'ai suivi un tutoriel sur Internet qui correspondait assez à ma situation expérimentale. En revanche, il me reste quelques questions en suspens pour le choix de ces différentes options...
Dans SPSS, le tableau de résultats comprend cinq variables :
- la valence (variable renseignée par le participant pour chaque présentation de stimuli, et qui correspond à un score compris entre 1 à 9)
- le couple (qui correspond au stimulus présenté, et qui sert de base au codage en positif/neutre/négatif)
- la valeur de "Positif" pour le couple considéré, 0 ou 1
- la valeur de "Neutre"
- la valeur de "Négatif"
A partir de là, j'ai choisi le menu Analyse > Modèles linéaires Généralisés > Modèles linéaires Généralisés
Pour l'onglet modèle, j'ai choisi Réponse ordinale > Logistique ordinale
(parce que ma variable dépendante est ordinale)
Pour l'onglet réponse, j'ai placé la valence renseignée par l'utilisateur en tant que variable dépendante
Pour l'onglet Prédicteurs, j'ai placé les variables Positif, Neutre, et Négatif en facteurs
Pour l'onglet Modèle, j'ai également placé les variables Positif, Neutre, et Négatif en facteurs comme "effets principaux" (mais je ne sais pas à quoi correspondent les autres options, notamment "factoriel" ou "interaction")
Pour l'onglet Estimation, méthode Fischer
Pour l'onglet Statistiques, j'inclue les estimations des paramètres de la distribution exponentielle
J'ai suivi un tutoriel sur Internet qui correspondait assez à ma situation expérimentale. En revanche, il me reste quelques questions en suspens pour le choix de ces différentes options...
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Eric Wajnberg Lun 19 Oct 2015 - 11:30
Je crois bien comprendre à présent ce que vous avez fait.
Il s'agit donc d'une régression logistique ordinale effectivement, et c'est un choix possible (parmi d'autres). Si on appelle p la probabilité qu'un individu ait un valence de i (i est compris en 0 et 9), alors le modèle que vous ajustez est :
Ce modèle peut être ré-écrit sous la forme suivante :
Dans ce cas, on reste bien sur ce que j'ai dit précédemment, à savoir
J'espère que c'est clair pour vous.
Cordialement, Eric.
Il s'agit donc d'une régression logistique ordinale effectivement, et c'est un choix possible (parmi d'autres). Si on appelle p la probabilité qu'un individu ait un valence de i (i est compris en 0 et 9), alors le modèle que vous ajustez est :
- Code:
Log(p/(1-p))=a1x1 + a2x2 + a3x3 + ..
Ce modèle peut être ré-écrit sous la forme suivante :
- Code:
p=exp(1x1 + a2x2 + a3x3 + ..)/(1+exp(1x1 + a2x2 + a3x3 + ..))
Dans ce cas, on reste bien sur ce que j'ai dit précédemment, à savoir
Ainsi donc, si on prend comme exemple le régresseur "Positif" et si on prend sa valeur de 1 comme une référence (c'est ce qui semble être le choix de votre logiciel), on remarque que, à la valeur 0 de ce régresseur, le paramètre de régression estimé vaut -0.844, ce qui signifie que la prévalence diminue chez les sujets concernés (car ce paramètre est négatif), et ce de manière fortement significative (chi2=15.295, pour 1 df, p<0.001). Dit autrement, la prévalence augmente si "Positif" passe de 0 à 1. Etc.les paramètres négatifs ont une influence négative sur la variable modélisée. Les paramètres positifs ont une influence positive. Ceci est à relativiser à leur erreur standard (improprement appelés "résidu standard" dans les sorties que vous nous montrez), et donc à leur significativité statistique (voir les colonnes test d'hypothèse). La valeur exp(B) est juste l'exponentiel des paramètres.
J'espère que c'est clair pour vous.
Cordialement, Eric.
Eric Wajnberg- Nombre de messages : 1238
Date d'inscription : 14/09/2012
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Yak Mar 20 Oct 2015 - 6:39
Merci beaucoup pour vos explications.
Je dois avouer que c'est encore un peu confus pour moi.
Avant tout, je ne comprends pas à quoi correspond p : dans mon esprit, la probabilité d'obtenir un score de valence compris entre 1 et 9 vaut toujours 1 puisque toutes les réponses se situent dans cette fenêtre...
En utilisant les données du tableau de résultat, la formule s'écrirait donc comme ceci :
Est-il possible de comparer les coefficients ? Par exemple, peut-on dire qu'un stimulus négatif aurait environ 5 fois plus de poids sur le ressenti qu'un stimulus positif ?
Peut-on définir la "prévalence" comme l'influence du stimulus sur le ressenti exprimé par le participant ?
En fait, j'espérais idéalement identifier une relation permettant de prévoir (avec un seuil de confiance) le score de valence ressentie en fonction de la valence individuelle de chaque stimulus présenté. Une fonction idéale qui ressemblerait à :
Je dois avouer que c'est encore un peu confus pour moi.
Avant tout, je ne comprends pas à quoi correspond p : dans mon esprit, la probabilité d'obtenir un score de valence compris entre 1 et 9 vaut toujours 1 puisque toutes les réponses se situent dans cette fenêtre...
En utilisant les données du tableau de résultat, la formule s'écrirait donc comme ceci :
- Code:
p=exp(régresseurs)/(1+exp(régresseurs))
avec régresseurs = -0,844 x Pos + 0,288 x Neu + 3,790 x Neg
Est-il possible de comparer les coefficients ? Par exemple, peut-on dire qu'un stimulus négatif aurait environ 5 fois plus de poids sur le ressenti qu'un stimulus positif ?
Peut-on définir la "prévalence" comme l'influence du stimulus sur le ressenti exprimé par le participant ?
En fait, j'espérais idéalement identifier une relation permettant de prévoir (avec un seuil de confiance) le score de valence ressentie en fonction de la valence individuelle de chaque stimulus présenté. Une fonction idéale qui ressemblerait à :
- Code:
valence ressentie = f(StimulusA, StimulusB)
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Eric Wajnberg Mar 20 Oct 2015 - 10:05
Dans mon explication, p n'est pas la probabilité d'obtenir un score de valence compris entre 1 et 9, mais - séparément - la probabilité d'obtenir un score de valence de 1, ou de 2, .., ou de 9, parmi tout les scores possibles. C'est votre choix de partir sur une régression logisitique qui impose cette structure, puisque vous imposez d'être dans un cadre multinomial.Yak a écrit:Avant tout, je ne comprends pas à quoi correspond p : dans mon esprit, la probabilité d'obtenir un score de valence compris entre 1 et 9 vaut toujours 1 puisque toutes les réponses se situent dans cette fenêtre...
Ce n'est pas simple (par pour moi en tout cas). Je pense que c'est possible, puisqu'on a l'estimation des paramètres et leur erreur standard. On devrait pouvoir construire des contrastes, mais je n'ai jamais fait ca. Désolé.Yak a écrit:
Est-il possible de comparer les coefficients ? Par exemple, peut-on dire qu'un stimulus négatif aurait environ 5 fois plus de poids sur le ressenti qu'un stimulus positif ?
C'est vous qui avez défini ce paramètre. C'est vous seul qui pouvez dire quel est sa signification biologique. Ce n'est pas un problème de statistique et d'analyse des données.Yak a écrit:Peut-on définir la "prévalence" comme l'influence du stimulus sur le ressenti exprimé par le participant ?
Ce n'est pas ambitieux. C'est exactement au contraire l'objectif de la régression que vous ajustez, et grâce à laquelle vous pouvez effectivement prédire la valence en fonction des valeurs des régresseurs.Yak a écrit:En fait, j'espérais idéalement identifier une relation permettant de prévoir (avec un seuil de confiance) le score de valence ressentie en fonction de la valence individuelle de chaque stimulus présenté. Une fonction idéale qui ressemblerait à :Ces résultats permettraient-ils d'aboutir à un calcul prévisionnel, ou est-ce trop ambitieux ?
- Code:
valence ressentie = f(StimulusA, StimulusB)
Eric.
Eric Wajnberg- Nombre de messages : 1238
Date d'inscription : 14/09/2012
Re: Interprétation des résultats Modèles Linéaires Généralisés
par Yak Mar 20 Oct 2015 - 16:43
Merci beaucoup pour l'ensemble de vos réponses.
C'est maintenant un peu plus clair pour moi.
Je vais essayer de trouver comment passer de la formule du modèle à la fonction de prédiction...
Merci encore !
C'est maintenant un peu plus clair pour moi.
Je vais essayer de trouver comment passer de la formule du modèle à la fonction de prédiction...
Merci encore !
Yak- Nombre de messages : 9
Date d'inscription : 26/09/2015
Contenu sponsorisé
» indicateur adéquation modèles non linéaires
» modèles linéaires mixtes vs/ anova pour plan factoriel
» Régressions linéaires multiples et comparaison des résultats
» interprétation résultats
» Interprétation des résultats d'une régréssion linéaire
» modèles linéaires mixtes vs/ anova pour plan factoriel
» Régressions linéaires multiples et comparaison des résultats
» interprétation résultats
» Interprétation des résultats d'une régréssion linéaire
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum|
|
|