
Les posteurs les plus actifs de la semaine
| Aucun utilisateur |
Sujets les plus vus
Comparaison des techniques d'analyse / data mining
4 participants
Page 1 sur 1

Comparaison des techniques d'analyse / data mining
par Stephanie8587 Lun 24 Oct 2011 - 15:01
Bonjour,
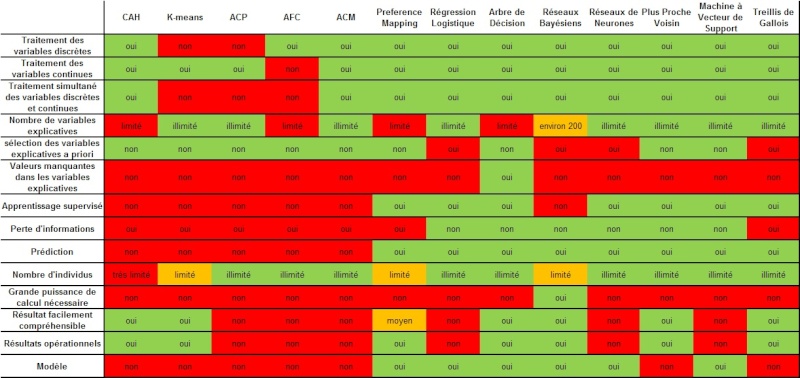
J'ai réalisé un tableau comparatif de différentes techniques de data mining existantes mais je ne suis pas certaine que tout soit correct..
Si vous avez des commentaires ou suggestions, je suis preneuse!!
Merci beaucoup pour votre aide
J'ai réalisé un tableau comparatif de différentes techniques de data mining existantes mais je ne suis pas certaine que tout soit correct..
Si vous avez des commentaires ou suggestions, je suis preneuse!!
Merci beaucoup pour votre aide
Stephanie8587- Nombre de messages : 3
Date d'inscription : 13/10/2011
Re: Comparaison des techniques d'analyse / data mining
par droopy Mar 25 Oct 2011 - 7:14
Bonjour,
Après il faudrait que tu donnes les définitions, ou ce que tu sous entends pour chaque ligne. Par exemple pour moi dans une ACM tu ne peux pas utiliser de variable continues, c'est comme le nombre de variables explicatives effectivement il peut-être illimité mais sans avoir de sens.
Avec l'ACP il est aussi possible de faire des prédictions. C'est pareil je ne vois pas pourquoi dans le kmeans tu as un nombre d’individus illimité. Pour ce qui est du plus proche voisin j'aurai mis qu'il faut une grande puissance de calcul surtout si le nombre d'individus est grand.
Après il faudrait que tu donnes les définitions, ou ce que tu sous entends pour chaque ligne. Par exemple pour moi dans une ACM tu ne peux pas utiliser de variable continues, c'est comme le nombre de variables explicatives effectivement il peut-être illimité mais sans avoir de sens.
Avec l'ACP il est aussi possible de faire des prédictions. C'est pareil je ne vois pas pourquoi dans le kmeans tu as un nombre d’individus illimité. Pour ce qui est du plus proche voisin j'aurai mis qu'il faut une grande puissance de calcul surtout si le nombre d'individus est grand.
droopy- Nombre de messages : 1156
Date d'inscription : 04/09/2009

Re: Comparaison des techniques d'analyse / data mining
par Nik Mar 25 Oct 2011 - 8:55
Salut,
Je ne sais pas pourquoi tu fais ce tableau de comparaison mais il me parait un peu bizarre. Effectivement, comme le souligne Droopy, il y a des problèmes de définition des critères et ensuite d'objectivité des critères.
J'ajoute :
- la distinction variable "discrète" et "continue" n'est pas bonne. Un effectif est une variable discrète et on peut faire une ACP dessus. Les termes appropriés sont qualitatives (nominales et ordinales) et quantitatives
- je ne comprends pas le critère "sélection de variables explicatives à priori" : on peut toujours (on devrait même toujours) sélectionner des variables avec certains à priori qui sont en fait des hypothèses sur les données.
- de même pour "perte d'information" : toutes les analyses représentent une perte d'information car on est obligé d'avoir au moins l'existence d'une "erreur" qui est bien de la perte d'information même si on considère que c'est du bruit.
- "résultat facilement compréhensible" : c'est très très subjectif comme critère. Dire que le kmeans présente des résultats facilement compréhensible c'est faux car interpréter un kmeans sur le fond est plutôt fastidieux voire même bancal car la construction des groupes est très influencée par l'algorithme dont le fonctionnement est toujours écarté des interprétations.
- je ne comprends pas le critère "résultats opérationnels"
Nik
Je ne sais pas pourquoi tu fais ce tableau de comparaison mais il me parait un peu bizarre. Effectivement, comme le souligne Droopy, il y a des problèmes de définition des critères et ensuite d'objectivité des critères.
J'ajoute :
- la distinction variable "discrète" et "continue" n'est pas bonne. Un effectif est une variable discrète et on peut faire une ACP dessus. Les termes appropriés sont qualitatives (nominales et ordinales) et quantitatives
- je ne comprends pas le critère "sélection de variables explicatives à priori" : on peut toujours (on devrait même toujours) sélectionner des variables avec certains à priori qui sont en fait des hypothèses sur les données.
- de même pour "perte d'information" : toutes les analyses représentent une perte d'information car on est obligé d'avoir au moins l'existence d'une "erreur" qui est bien de la perte d'information même si on considère que c'est du bruit.
- "résultat facilement compréhensible" : c'est très très subjectif comme critère. Dire que le kmeans présente des résultats facilement compréhensible c'est faux car interpréter un kmeans sur le fond est plutôt fastidieux voire même bancal car la construction des groupes est très influencée par l'algorithme dont le fonctionnement est toujours écarté des interprétations.
- je ne comprends pas le critère "résultats opérationnels"
Nik
Nik- Nombre de messages : 1606
Date d'inscription : 23/05/2008
Re: Comparaison des techniques d'analyse / data mining
par Stephanie8587 Mar 25 Oct 2011 - 14:46
Bonjour et merci pour vos réponses,
Alors, pour les critères :
- traitement des variables discrètes : il s'agît bien du traitement en entrée des variables qualitatives (nominales et/ou ordinales)
- traitement des variables continues : traitement en entrée des variables quantitatives (je considère que le traitement est pris en compte même si l'algo discrétise la variable)
- traitement simultané : toujours en considérant que l'algo discrétise les variables continues
- Nombre de variables explicatives : j'ai bien noté que cette ligne n'avait pas beaucoup de sens mais je souhaitais simplement faire ressortir le fait qu'il existe des algo plus ou moins adaptés à certaines tailles de bases de données. Si vous avez une suggestion de présentation pour faire passer ce message...
- Sélection de variables explicatives a priori : ce qu'on envoie à l'algo (base complète ou base déjà sélectionnée de manière non automatique)
- Valeurs manquantes : prise en compte ou non des vides
- Apprentissage supervisé : cherche-t-on à expliquer une variable Y?
- Perte d'information : perte d'information due à l'algo et non aux "erreurs" considérées comme du bruit (ex : pour l'ACP, on sélectionne un certain nombre de composantes principales qui représentent 70% de l'information de départ, donc nous observons une perte de 30% de l'information)
- Prédiction : l'algo a-t-il un caractère prédictif?
- Nombre d'individus : même remarque que pour le nombre de variables explicatives...
- Puissance de calcul nécessaire : à taille de base égale
J'avais hésité à mettre "Temps de calcul à puissance égale" (rapide, long, très long) mais comme ces algos sont faits pour des bases de taille différente, je ne sais pas trop comment intituler ni comment remplir cette ligne..
- Résultat facilement compréhensible : J'avoue, c'est très subjectif... Mais disons que ces résultats sont plus ou moins compréhensibles par des personnes n'ayant pas forcément un bagage statistique
- Résultats opérationnels : résultats directement exploitable par des personnes n'ayant pas forcément de bagage statistique (par exemple, j'ai lu le tutoriel sur le Preference Mapping d'XLStat, on identifie un groupe de personnes qui aime tel type de chips, et après on va regarder les caractéristiques des chips (salées et grasses) : on pourrait directement exploiter ce résultat pour fabriquer et vendre des chips qui plaisent à un public ciblé de consommateurs).
- Modèle : Est ce qu'on cherche à déterminer un modèle par cette méthode ?
J'ai bien pris note que k-means était une méthode plus complexe que je ne le pensais, que l'ACP avait un caractère prédictif.
@Droopy : Par rapport à ce que tu disais sur l'ACM, maintenant que j'ai redéfini les deux premières lignes, confirmes-tu ton point de vue car j'ai lu que l'algo traitait aussi bien les variables qualitatives que quantitatives?
Pour ce qui est du plus proche voisin, je peux ajouter une ligne "dépendance au nombre d'individus" en précisant "linéaire".
@Nik : Je pense avoir intégré une réponse à toutes tes remarques dans la définition des différentes lignes.
Si vous avez d'autres remarques, n'hésitez pas!
Alors, pour les critères :
- traitement des variables discrètes : il s'agît bien du traitement en entrée des variables qualitatives (nominales et/ou ordinales)
- traitement des variables continues : traitement en entrée des variables quantitatives (je considère que le traitement est pris en compte même si l'algo discrétise la variable)
- traitement simultané : toujours en considérant que l'algo discrétise les variables continues
- Nombre de variables explicatives : j'ai bien noté que cette ligne n'avait pas beaucoup de sens mais je souhaitais simplement faire ressortir le fait qu'il existe des algo plus ou moins adaptés à certaines tailles de bases de données. Si vous avez une suggestion de présentation pour faire passer ce message...
- Sélection de variables explicatives a priori : ce qu'on envoie à l'algo (base complète ou base déjà sélectionnée de manière non automatique)
- Valeurs manquantes : prise en compte ou non des vides
- Apprentissage supervisé : cherche-t-on à expliquer une variable Y?
- Perte d'information : perte d'information due à l'algo et non aux "erreurs" considérées comme du bruit (ex : pour l'ACP, on sélectionne un certain nombre de composantes principales qui représentent 70% de l'information de départ, donc nous observons une perte de 30% de l'information)
- Prédiction : l'algo a-t-il un caractère prédictif?
- Nombre d'individus : même remarque que pour le nombre de variables explicatives...
- Puissance de calcul nécessaire : à taille de base égale
J'avais hésité à mettre "Temps de calcul à puissance égale" (rapide, long, très long) mais comme ces algos sont faits pour des bases de taille différente, je ne sais pas trop comment intituler ni comment remplir cette ligne..
- Résultat facilement compréhensible : J'avoue, c'est très subjectif... Mais disons que ces résultats sont plus ou moins compréhensibles par des personnes n'ayant pas forcément un bagage statistique
- Résultats opérationnels : résultats directement exploitable par des personnes n'ayant pas forcément de bagage statistique (par exemple, j'ai lu le tutoriel sur le Preference Mapping d'XLStat, on identifie un groupe de personnes qui aime tel type de chips, et après on va regarder les caractéristiques des chips (salées et grasses) : on pourrait directement exploiter ce résultat pour fabriquer et vendre des chips qui plaisent à un public ciblé de consommateurs).
- Modèle : Est ce qu'on cherche à déterminer un modèle par cette méthode ?
J'ai bien pris note que k-means était une méthode plus complexe que je ne le pensais, que l'ACP avait un caractère prédictif.
@Droopy : Par rapport à ce que tu disais sur l'ACM, maintenant que j'ai redéfini les deux premières lignes, confirmes-tu ton point de vue car j'ai lu que l'algo traitait aussi bien les variables qualitatives que quantitatives?
Pour ce qui est du plus proche voisin, je peux ajouter une ligne "dépendance au nombre d'individus" en précisant "linéaire".
@Nik : Je pense avoir intégré une réponse à toutes tes remarques dans la définition des différentes lignes.
Si vous avez d'autres remarques, n'hésitez pas!
Stephanie8587- Nombre de messages : 3
Date d'inscription : 13/10/2011
Re: Comparaison des techniques d'analyse / data mining
par gg Mar 25 Oct 2011 - 18:52
Bonjour.
Ce ne sont pas des stats, mais de la présentation : J'ai été surpris du choix des couleurs dans la ligne "grande puissance de calcul nécessaire". Il me semblait que "non" était plus agréable que "oui".
Cordialement
Ce ne sont pas des stats, mais de la présentation : J'ai été surpris du choix des couleurs dans la ligne "grande puissance de calcul nécessaire". Il me semblait que "non" était plus agréable que "oui".
Cordialement
gg- Nombre de messages : 2174
Date d'inscription : 10/01/2011
Re: Comparaison des techniques d'analyse / data mining
par Nik Mar 25 Oct 2011 - 20:21
Non on n'est pas obligé de ne retenir que 70% de l'info. On peut présenter différents plans factoriels s'ils sont interprétable. En régression c'est la même chose, les variables X expliquent une certaine part de la variabilité (le R² de la régression linéaire) et on a une variance résiduelle qui elle est une info non expliquée. C'est le même principe.- Perte d'information : perte d'information due à l'algo et non aux "erreurs" considérées comme du bruit (ex : pour l'ACP, on sélectionne un certain nombre de composantes principales qui représentent 70% de l'information de départ, donc nous observons une perte de 30% de l'information)
Je rejoins gg sur les couleurs, pour un néophyte le rouge va avoir une connotation négative. Pour donner un exemple supplémentaire, le choix à priori des variables doit être encouragé s'il se fait sur la base d'hypothèse raisonnable. Les procédures automatiques ne donnent rien de bon
je suis toujours pas très convaincu par ces rubriques. Des résultats faciles à interpréter et à utiliser en stat, c'est illusoire...
- Résultats opérationnels : [...]
- Résultat facilement compréhensible : [...]
Nik- Nombre de messages : 1606
Date d'inscription : 23/05/2008
Re: Comparaison des techniques d'analyse / data mining
par droopy Mer 26 Oct 2011 - 9:16
variable discrète : Pour AFc je suis partagé parce qu'effectivement certains font des AFC sur des variables ordinales, mais je ne suis pas sur que ce soit très pertinent puisque l'AFC est fait à la base pour traier des tables de contingence.
Variables continues : Pas d'accord pour ACM, ce n'est pas l'algo mais l'utilisateur dans ce cas qui va discrétiser la variable, ce qui n'est pas la même chose.
Traitement simultané : idem.
Nombre de variable explicative : effectivement variable très suggestive ... Si tu gardes ton raisonnement de départ je ne vois pas pourquoi une AFC et une ACM pourrait avoir un nombre illimité de variables et pas l'ACM. De plus pour tous ce qui est des modèles (a part les modèles de types PLS) ils me semblent que le nombre de variable explicative n'a pas lieu de dépasser le nombre d'individus, et donc pas lieu d'être illimité. J'aurai plutôt tendance a penser le contraire.
Sélection des variables explicatives a priori : La aussi c'est subjectif.
Valeurs manquantes : me semble ok mais pas connait pas trop les svm
apprentissage supervisé : ok
perte d'information : ok
prédiction : avec ta def je change mon opinion sur l'ACP, il est clair que l'algo n'a pas un but prédictif. Après est-ce que cette ligne ne devrait pas être la même que celle de l'apprentissage supervisé ? Vérifie tes sorties pour les réseaux bayésiens.
Nombre d'individus : Avec ta def (sélection ou non d'individus a priori) alors je mettrais illimité partout
Grande puissance de calcul : tout est relatif aux nombres d'individus. Une CAH peut-être assez gourmande si tu as bcp d'individus, pareil pour un kmeans, pareil pour le plus proche voisin, pour le réseau de neurones je n'en sais rien
Résultat facilement accessible : comme tu le dis c'est très subjectif, par exemple je ne suis pas d'accord pour l'ACP, l'AFC et l'ACM
résultat opérationnel : ok
modèle : ok
Variables continues : Pas d'accord pour ACM, ce n'est pas l'algo mais l'utilisateur dans ce cas qui va discrétiser la variable, ce qui n'est pas la même chose.
Traitement simultané : idem.
Nombre de variable explicative : effectivement variable très suggestive ... Si tu gardes ton raisonnement de départ je ne vois pas pourquoi une AFC et une ACM pourrait avoir un nombre illimité de variables et pas l'ACM. De plus pour tous ce qui est des modèles (a part les modèles de types PLS) ils me semblent que le nombre de variable explicative n'a pas lieu de dépasser le nombre d'individus, et donc pas lieu d'être illimité. J'aurai plutôt tendance a penser le contraire.
Sélection des variables explicatives a priori : La aussi c'est subjectif.
Valeurs manquantes : me semble ok mais pas connait pas trop les svm
apprentissage supervisé : ok
perte d'information : ok
prédiction : avec ta def je change mon opinion sur l'ACP, il est clair que l'algo n'a pas un but prédictif. Après est-ce que cette ligne ne devrait pas être la même que celle de l'apprentissage supervisé ? Vérifie tes sorties pour les réseaux bayésiens.
Nombre d'individus : Avec ta def (sélection ou non d'individus a priori) alors je mettrais illimité partout
Grande puissance de calcul : tout est relatif aux nombres d'individus. Une CAH peut-être assez gourmande si tu as bcp d'individus, pareil pour un kmeans, pareil pour le plus proche voisin, pour le réseau de neurones je n'en sais rien
Résultat facilement accessible : comme tu le dis c'est très subjectif, par exemple je ne suis pas d'accord pour l'ACP, l'AFC et l'ACM
résultat opérationnel : ok
modèle : ok
droopy- Nombre de messages : 1156
Date d'inscription : 04/09/2009
Re: Comparaison des techniques d'analyse / data mining
par Invité Mer 26 Oct 2011 - 12:10
Tout ce que j'avais comme remarque a été dit, sauf pour les réseaux bayésiens:
Supportent très bien les valeurs manquantes (pareil pour l'analyse factorielles, beaucoup d'algo permettant de traiter les données manquantes, cf le package R MissMDA, mais il est vrai que cela traite plutot de l'imputation que de traiter directement les données en présence de données manquantes dans les analyses factorielles)
Pas d'accord avec toi sur le nombre de variables, j'ai déjà traité plus de 400 variables avec BayesiaLab,
Possibilité de faire des apprentissages supervisés (couverture de Markov de la variables cible, Markov augmenté avec Max Spanning Tree... bref bcp d'algo disponibles)
Perso je vois pas en quoi on sélectionne plus les variables en réseaux bayésiens qu'en ACP...
De même, le nombre d'individu est plutot illimité à mes yeux (je suis sur un fichier de 12000 individus actuellement)...
Voila, pour mes corrections et remarques!
Cordialement
Supportent très bien les valeurs manquantes (pareil pour l'analyse factorielles, beaucoup d'algo permettant de traiter les données manquantes, cf le package R MissMDA, mais il est vrai que cela traite plutot de l'imputation que de traiter directement les données en présence de données manquantes dans les analyses factorielles)
Pas d'accord avec toi sur le nombre de variables, j'ai déjà traité plus de 400 variables avec BayesiaLab,
Possibilité de faire des apprentissages supervisés (couverture de Markov de la variables cible, Markov augmenté avec Max Spanning Tree... bref bcp d'algo disponibles)
Perso je vois pas en quoi on sélectionne plus les variables en réseaux bayésiens qu'en ACP...
De même, le nombre d'individu est plutot illimité à mes yeux (je suis sur un fichier de 12000 individus actuellement)...
Voila, pour mes corrections et remarques!
Cordialement
Invité- Invité
Re: Comparaison des techniques d'analyse / data mining
par Stephanie8587 Jeu 10 Nov 2011 - 15:17
Bonjour à tous et merci pour tous vos commentaires. J'ai modifié mon tableau en fonction de toutes vos remarques.
Je le laisse à disposition et si jamais vous avez d'autres suggestions, n'hésitez pas!

Je le laisse à disposition et si jamais vous avez d'autres suggestions, n'hésitez pas!
Stephanie8587- Nombre de messages : 3
Date d'inscription : 13/10/2011
» Data mining
» ACP Haberman's survival data set
» Logiciel de Data-Mining WEKA
» modèle économétrique et data.
» Utiliser techniques de classification ou de prédiction?
» ACP Haberman's survival data set
» Logiciel de Data-Mining WEKA
» modèle économétrique et data.
» Utiliser techniques de classification ou de prédiction?
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum