
Les posteurs les plus actifs de la semaine
| Aucun utilisateur |
Sujets les plus vus
Comparaison de moyennes variable discrète
3 participants
Page 1 sur 1

Comparaison de moyennes variable discrète
par louiv Sam 7 Juil 2018 - 10:02
Bonjour à tous,
J'ai un problème de statistique a résoudre. Ayant que de faibles bases, j'ai essayé de monter mon raisonnement grâce aux ressources trouvés sur le net. J'aimerai avoir votre avis sur ma démarche et mes questions...
Je souhaite comparer différentes modalités de traitements appliqués sur des arbres fruitiers. Pour cela, j'ai récolté 20 fruits par modalité. Il y a 4 répétitions (4 arbres par modalité), j'ai donc récolté 5 fruits par arbre.
Ces fruits sont stockés et le nombre de fruits infectés pour chacun des 4 répétitions de la modalité est relevé au bout de 7 jours. J'ai donc une variable discrète (nb de fruits pourris).
Afin de gagner en précision, j'ai mis de côté pour certaines modalité 1 répétition qui présente la moyenne la plus éloignée de la médiane. Je me retrouve donc avec 12 modalités comprenant 3 ou 4 répétitions.
AI-je le droit de virer une répétition ? Est-ce que les échantillons doivent avoir le même effectif pour pouvoir être comparés (ANOVA1 ou Student) ? Est-ce que le fait que ma variable soit discontinue change quelque chose POUR pour les tests ?
Afin de déterminer si les traitements ont des efficacités différentes, j'ai voulu réaliser une ANOVA à 1 dimension (avec le logiciel Minitab). Pour cela on suppose que la variable suit une loi normale. Comme j'ai des échantillons petits (N= 3 ou 4) il m'est impossible de le prouver par un test de normalité (donc on suppose).
De plus, les variances doivent-être égales. J'ai donc réalisé un test d'égalité des variances, j'obtiens :
- Pour le test de comparaison multiple : p=0,85 (alpha = 0,05)
- Pour le test de Levene :p= 0,39
Du coup les variances ne sont pas égales... je dois donc faire un test non paramétrique ? le test de Mann & Whitney, ou bien le test de Kruskal-Wallis ?
Je lance quand même mon ANOVA 1 "pour voir", et là, premier problème : un message d'erreur s'affiche : au moins deux valeurs distinctes sont obligatoire pour chaque échantillon. Du coup, je ne peux pas inclure dans le test les modalités présentant le même nombre de fruits pourris pour chacune des répétitions (caractérisés par un écart-type nul). Je les exclue donc, et je trouve que il n'y a pas de différence significative entre mes modalités (enfin entre celles pouvant être testés) pour un alpha =0,05.
Mais comment savoir si il y a une différence significative entre les modalités testées et celles impossible à tester ? Le fait que l'écart-type soit nul est suffisant pour dire que l'effet du traitement est significativement différents des autres ? je ne pense pas....
J'ai pensé faire un test t de Student pour comparer chaque échantillon au témoin. Là même problème, je ne peux pas comparer le traitement A (2,2,2,2) avec le témoin (1,3,3) Mais à l'inverse de L'ANOVA1, je trouve quand je compare certains de mes échantillons au témoin une différence significative.
Mais à l'inverse de L'ANOVA1, je trouve quand je compare certains de mes échantillons au témoin une différence significative.
Comment conclure sur mes résultats ? Qui croire, ANOVA ou Student ?
Quid de la comparaison de proportion ? Est-ce que ce test peut s'appliquer à mon cas ?
Voila voila, je vous remercie d'avance pour votre aide !
Louiv
J'ai un problème de statistique a résoudre. Ayant que de faibles bases, j'ai essayé de monter mon raisonnement grâce aux ressources trouvés sur le net. J'aimerai avoir votre avis sur ma démarche et mes questions...
Je souhaite comparer différentes modalités de traitements appliqués sur des arbres fruitiers. Pour cela, j'ai récolté 20 fruits par modalité. Il y a 4 répétitions (4 arbres par modalité), j'ai donc récolté 5 fruits par arbre.
Ces fruits sont stockés et le nombre de fruits infectés pour chacun des 4 répétitions de la modalité est relevé au bout de 7 jours. J'ai donc une variable discrète (nb de fruits pourris).
Afin de gagner en précision, j'ai mis de côté pour certaines modalité 1 répétition qui présente la moyenne la plus éloignée de la médiane. Je me retrouve donc avec 12 modalités comprenant 3 ou 4 répétitions.
AI-je le droit de virer une répétition ? Est-ce que les échantillons doivent avoir le même effectif pour pouvoir être comparés (ANOVA1 ou Student) ? Est-ce que le fait que ma variable soit discontinue change quelque chose POUR pour les tests ?
Afin de déterminer si les traitements ont des efficacités différentes, j'ai voulu réaliser une ANOVA à 1 dimension (avec le logiciel Minitab). Pour cela on suppose que la variable suit une loi normale. Comme j'ai des échantillons petits (N= 3 ou 4) il m'est impossible de le prouver par un test de normalité (donc on suppose).
De plus, les variances doivent-être égales. J'ai donc réalisé un test d'égalité des variances, j'obtiens :
- Pour le test de comparaison multiple : p=0,85 (alpha = 0,05)
- Pour le test de Levene :p= 0,39
Du coup les variances ne sont pas égales... je dois donc faire un test non paramétrique ? le test de Mann & Whitney, ou bien le test de Kruskal-Wallis ?
Je lance quand même mon ANOVA 1 "pour voir", et là, premier problème : un message d'erreur s'affiche : au moins deux valeurs distinctes sont obligatoire pour chaque échantillon. Du coup, je ne peux pas inclure dans le test les modalités présentant le même nombre de fruits pourris pour chacune des répétitions (caractérisés par un écart-type nul). Je les exclue donc, et je trouve que il n'y a pas de différence significative entre mes modalités (enfin entre celles pouvant être testés) pour un alpha =0,05.
Mais comment savoir si il y a une différence significative entre les modalités testées et celles impossible à tester ? Le fait que l'écart-type soit nul est suffisant pour dire que l'effet du traitement est significativement différents des autres ? je ne pense pas....
J'ai pensé faire un test t de Student pour comparer chaque échantillon au témoin. Là même problème, je ne peux pas comparer le traitement A (2,2,2,2) avec le témoin (1,3,3)
Comment conclure sur mes résultats ? Qui croire, ANOVA ou Student ?
Quid de la comparaison de proportion ? Est-ce que ce test peut s'appliquer à mon cas ?
Voila voila, je vous remercie d'avance pour votre aide !
Louiv
louiv- Nombre de messages : 5
Date d'inscription : 25/06/2018
Re: Comparaison de moyennes variable discrète
par Florent Aubry Mar 10 Juil 2018 - 20:56
Ton problème n'est pas un problème de comparaison de moyennes mais relève plutôt de la régression logistique avec comme question est-ce que la proportion de fruits avariés est la même pour toutes les modalités. Ni l'Anova ni STudent ne sont adaptés. Il faut donc analyser cela en utilisant un modèle de régression logisitique (modèle linéaire généralisée avec comme fonction de lien la fonction logit) et comme variable à expliquer le binôme : (nombre de fruits avariés, nombre de fruits sains). Maintenant 4 répétitions par modalité me paraît plutôt faible.
Une solution pourrait être de pooler les proportions par modalité et de faire un test d'homogénéité des proportions. Mais sur 12 modalités, il faudra vraiment qu'il y ait des différences très significatives.
Une solution pourrait être de pooler les proportions par modalité et de faire un test d'homogénéité des proportions. Mais sur 12 modalités, il faudra vraiment qu'il y ait des différences très significatives.
Florent Aubry- Nombre de messages : 251
Date d'inscription : 02/11/2015
Re: Comparaison de moyennes variable discrète
par louiv Lun 16 Juil 2018 - 11:00
Merci Florent pour ta réponse.
J'ai donc effectué une regression logistique binaire. Mais là encore, plusieurs problèmes se posent et je ne sais pas trop comment interpréter les résultats.
- Je ne peux toujours pas analyser les modalités qui n'ont pas 2 valeurs différentes (Par exemple une modalité où j'ai 0 fruit infecté pour chacune des 4 répétitions).
- Je ne sais pas trop comment conclure : j'ai une p-value de 0,031, donc tous mes traitements sont significativement différents...? Je trouve cela étrange car par exemple les données de B et MP sont identiques donc les traitements ne doivent en théorie ne pas être significativement différents...?
- J'ai un R² vraiment très faible (30%). Le modèle ne colle donc pas vraiment aux données, du coup est-ce que je peux vraiment conclure quelque chose ?
- Les p-values des tests d'ajustements sont > 0,05 donc "les probabilités prévues ne diffèrent pas des probabilités observées d'une façon que ne prévoit pas la loi binomiale." J'ai du mal à comprendre concrètement cette affirmation.
- D'après ce que j'ai compris, le rapport des probabilités des différents traitements me donnent des indications sur la différence de probabilité d'avoir un succès (ici le succès est d'avoir un fruit infecté) entre les traitements. Prenons Eau (niveau A) et AP (niveau B) : le rapport des probabilités de succès est de 6. Cela veut donc dire que j'ai 6 fois plus de chance d'avoir un fruit infecté sur le traitement Eau (témoin) que sur le traitement AP ?
Voici les données que j'ai utilisé (je n'ai pas inclus les modalités qui présentent un écart-type nul car sinon message d'erreur), la fenêtre de selection des données pour la regression, ainsi que les résultats que me donnent minitab :
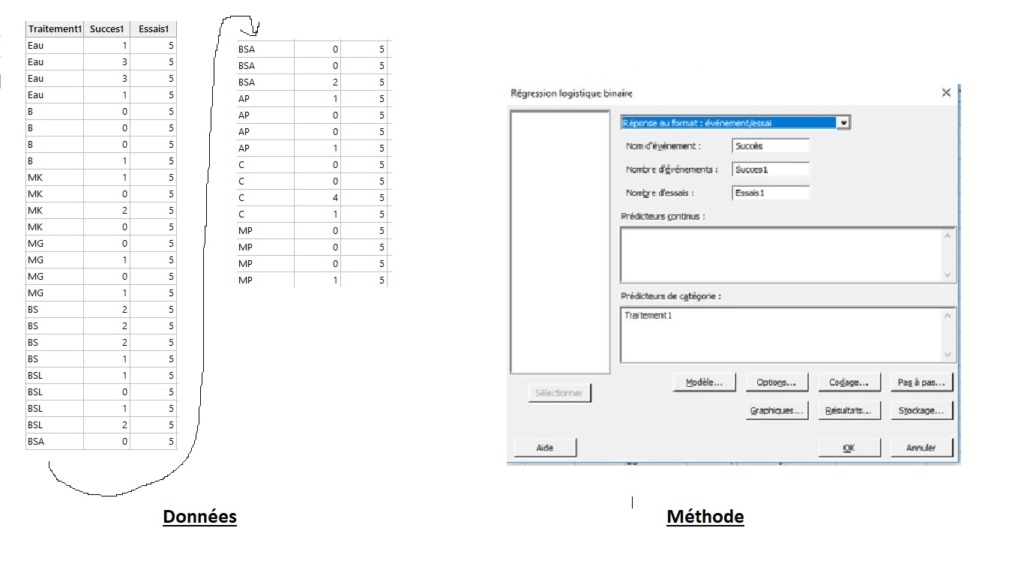

Merci d'avance pour votre aide,
Louis
J'ai donc effectué une regression logistique binaire. Mais là encore, plusieurs problèmes se posent et je ne sais pas trop comment interpréter les résultats.
- Je ne peux toujours pas analyser les modalités qui n'ont pas 2 valeurs différentes (Par exemple une modalité où j'ai 0 fruit infecté pour chacune des 4 répétitions).
- Je ne sais pas trop comment conclure : j'ai une p-value de 0,031, donc tous mes traitements sont significativement différents...? Je trouve cela étrange car par exemple les données de B et MP sont identiques donc les traitements ne doivent en théorie ne pas être significativement différents...?
- J'ai un R² vraiment très faible (30%). Le modèle ne colle donc pas vraiment aux données, du coup est-ce que je peux vraiment conclure quelque chose ?
- Les p-values des tests d'ajustements sont > 0,05 donc "les probabilités prévues ne diffèrent pas des probabilités observées d'une façon que ne prévoit pas la loi binomiale." J'ai du mal à comprendre concrètement cette affirmation.
- D'après ce que j'ai compris, le rapport des probabilités des différents traitements me donnent des indications sur la différence de probabilité d'avoir un succès (ici le succès est d'avoir un fruit infecté) entre les traitements. Prenons Eau (niveau A) et AP (niveau B) : le rapport des probabilités de succès est de 6. Cela veut donc dire que j'ai 6 fois plus de chance d'avoir un fruit infecté sur le traitement Eau (témoin) que sur le traitement AP ?
Voici les données que j'ai utilisé (je n'ai pas inclus les modalités qui présentent un écart-type nul car sinon message d'erreur), la fenêtre de selection des données pour la regression, ainsi que les résultats que me donnent minitab :
Merci d'avance pour votre aide,
Louis
louiv- Nombre de messages : 5
Date d'inscription : 25/06/2018
Re: Comparaison de moyennes variable discrète
par Eric Wajnberg Lun 16 Juil 2018 - 16:09
Deux points :
La variable analysée est le nombre de fruits pourris. C'est donc un comptage, si j'ai bien compris. Je me demande s'il ne conviendrait pas plutôt de partir sur une régression log-linéaire pour données de Poisson.
Enfin, non, on ne peux virer une répétition comme ceci. D'abord ca biaise les données. En plus vous perdez mécaniquement en puissance et vos tests seront moins efficaces à détecter des effets.
HTH, Eric.
La variable analysée est le nombre de fruits pourris. C'est donc un comptage, si j'ai bien compris. Je me demande s'il ne conviendrait pas plutôt de partir sur une régression log-linéaire pour données de Poisson.
Enfin, non, on ne peux virer une répétition comme ceci. D'abord ca biaise les données. En plus vous perdez mécaniquement en puissance et vos tests seront moins efficaces à détecter des effets.
HTH, Eric.

Eric Wajnberg- Nombre de messages : 1237
Date d'inscription : 14/09/2012
Re: Comparaison de moyennes variable discrète
par louiv Ven 20 Juil 2018 - 11:11
Merci Eric !! je pense que la régression pour données de Poisson est la plus adaptée, je vais rester là dessus !
J'ai encore un problème non résolu que je me traîne depuis le début : comment inclure dans l'analyse les modalité à écart-type nul ? (exemple: modalité X présentant 0 fruit avarié pour chaque répétition). Est-il possible de tirer des conclusions sans stats sur ces modalités à écart-type nul ? J'ai toujours un message d'erreur quand j'essaye de les inclure dans un test sur Minitab...
Merci d'avance,
Louis
J'ai encore un problème non résolu que je me traîne depuis le début : comment inclure dans l'analyse les modalité à écart-type nul ? (exemple: modalité X présentant 0 fruit avarié pour chaque répétition). Est-il possible de tirer des conclusions sans stats sur ces modalités à écart-type nul ? J'ai toujours un message d'erreur quand j'essaye de les inclure dans un test sur Minitab...
Merci d'avance,
Louis
louiv- Nombre de messages : 5
Date d'inscription : 25/06/2018
Re: Comparaison de moyennes variable discrète
par Eric Wajnberg Ven 20 Juil 2018 - 14:47
Si ces zéros peuvent être issue soit d'une processus de Poisson (un comptage qui donne zéro) soit d'un processus binomial (probabilité d'avoir un fruit pourri ou non) alors il vous faut plutot partir sur un "zero-inflated "Poisson (ZIP) model. Ca complique encore d'avantage l'analyse et il faut trouver des logiciels qui ajustent ce genre de choses (R fait ça très bien). D'après vos explications, j'ai l'impression que c'est ceci qui vous conviendrait.
Je ne sais quoi vous proposer d'autres.
HTH, Eric.
Je ne sais quoi vous proposer d'autres.
HTH, Eric.
Eric Wajnberg- Nombre de messages : 1237
Date d'inscription : 14/09/2012
» Comparaison de moyennes - variable dichotomique: QUEL TEST ?
» Corrélation entre variable continue et variable discrète
» Variable quantitative discrète
» lm pour variable discrète
» démographie: Variable quantitative discrète ou continue?
» Corrélation entre variable continue et variable discrète
» Variable quantitative discrète
» lm pour variable discrète
» démographie: Variable quantitative discrète ou continue?
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum|
|
|