
Les posteurs les plus actifs de la semaine
| Aucun utilisateur |
Sujets les plus vus
régression et non-normalité
2 participants
Page 1 sur 1

régression et non-normalité
par CupOfAppleTea Mar 26 Mar 2013 - 9:56
Bonjour,
Je souhaite procéder à une régression linéaire avec la fonction glm mais le test de normalité de shapiro-wilk sur les résidus de la régression est négatif. L'hétéroscédasticité des résidus n'est pas non plus respectée.
Que faire dans ce cas de figure? L'objectif de ma démarche est de comparer la pente de ma régression selon plusieurs conditions d'expérimentation (une régression par cas). Je souhaite donc récupérer l'estimateur du paramètre correspondant à la pente (je n'ai qu'une seule variable explicative).
D'après ce que j'ai lu sur les régression non-paramétriques, celles-ci ne fournissent pas ce type d'information. La seule solution qu'il me reste consiste donc à calculer un coefficient de correlation de type "spearman" qui semble convenir dans mon cas.
Est-ce que je passe à coté de quelque chose?
Merci pour votre aide!
Je souhaite procéder à une régression linéaire avec la fonction glm mais le test de normalité de shapiro-wilk sur les résidus de la régression est négatif. L'hétéroscédasticité des résidus n'est pas non plus respectée.
Que faire dans ce cas de figure? L'objectif de ma démarche est de comparer la pente de ma régression selon plusieurs conditions d'expérimentation (une régression par cas). Je souhaite donc récupérer l'estimateur du paramètre correspondant à la pente (je n'ai qu'une seule variable explicative).
D'après ce que j'ai lu sur les régression non-paramétriques, celles-ci ne fournissent pas ce type d'information. La seule solution qu'il me reste consiste donc à calculer un coefficient de correlation de type "spearman" qui semble convenir dans mon cas.
Est-ce que je passe à coté de quelque chose?
Merci pour votre aide!
CupOfAppleTea- Nombre de messages : 28
Date d'inscription : 14/12/2012
Re: régression et non-normalité
par Nik Mar 26 Mar 2013 - 18:35
Salut,
Nik
ce test indique vite une non-normalité dès qu'il y a beaucoup de données. Les méthodes graphiques que tu obtiens via la fonction plot.glm sont tout aussi efficaces que vouloir à tout prix avoir une p-value<0.05 qui ne veut rien dire.le test de normalité de shapiro-wilk
Là c'est beaucoup plus gênant mais il faut aller plus loin. D'où provient cette hétéroscédasticité ? Il faut que tu saches si c'est la distribution de base de tes données qui ne correspond pas à une hypothèse de variance constante des résidus ou si c'est un problème de plan d'échantillonnage par exemple. Suivant la réponse à cette question tu pourras envisager diverses solutions (modèles mixtes par exemple).L'hétéroscédasticité des résidus n'est pas non plus respectée.
--> très mauvaise pratique. Des paramètres issus de modèles différents ne sont pour ainsi dire pas comparables. Il vaut mieux t'orienter vers un modèle de type ANCOVA qui correspond tout simplement à l'introduction dans ton modèle d'un facteur qui code pour les conditions d'expérimentation et voir si ce facteur a un effet sur ta variable à prédire. Avec les coefficients associés à ce facteur tu pourras comparer les expérimentations. Attention toutefois au fait que R prend toujours une modalité témoin et effectue les comparaison par rapport à cette modalité.L'objectif de ma démarche est de comparer la pente de ma régression selon plusieurs conditions d'expérimentation (une régression par cas)
Je ne pratique pas ce genre de régression mais je ne vois pas trop pourquoi une régression robuste ne pourrait pas t'apporter ce genre d'info finalement assez basique.D'après ce que j'ai lu sur les régression non-paramétriques, celles-ci ne fournissent pas ce type d'information
au secours...ce genre de coefficient n'apporte quasiment aucune information. La transformation en rang est brutale et souvent assez stupide car l'organisation des données va bien plus loin qu'un simple agencement des valeurs dans un ordre ou un autre.La seule solution qu'il me reste consiste donc à calculer un coefficient de correlation de type "spearman" qui semble convenir dans mon cas.
Nik
Nik- Nombre de messages : 1606
Date d'inscription : 23/05/2008
Re: régression et non-normalité
par CupOfAppleTea Mer 27 Mar 2013 - 9:03
ce test indique vite une non-normalité dès qu'il y a beaucoup de données. Les méthodes graphiques que tu obtiens via la fonction plot.glm sont tout aussi efficaces
Dans mon cas je ne dispose pas d'une grande quantité de données et une visualisation graphique confirme que les données ne suivent pas une loi normale. C'est clair et net.
D'où provient cette hétéroscédasticité ? Il faut que tu saches si c'est la distribution de base de tes données qui ne correspond pas à une hypothèse de variance constante des résidus ou si c'est un problème de plan d'échantillonnage par exemple. Suivant la réponse à cette question tu pourras envisager diverses solutions (modèles mixtes par exemple).
Je ne comprends pas très bien le commentaire ici. Je pense que l'hétéroscédasticité de mes données est due à un pb d'échantillonnage. Si j'avais disposé de plus d'échantillons, l'homoscédasticité aurait été respectée.
Des paramètres issus de modèles différents ne sont pour ainsi dire pas comparables.
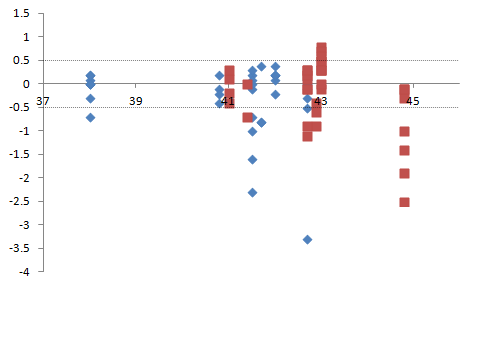
L'idée que j'évoquais ici était de comparer la valeur du paramètre d'un même modèle appliqué à différents pas de temps de mon expérimentation. Je ne pense pas donc que cela pose pb. Je ne compare pas des modèles différents. De plus, je n'ai qu'une seule variable codant pour ma condition d'expérimentation (température), l'ANCOVA ne servirait donc pas dans mon cas. En pièce jointe vous pourrez trouver un exemple graphique des données dont je dispose. En abscisse ma variable explicative (température) et en ordonnée la valeur prise par mes individus. Les individus ont été échantillonnés seulement selon qq valeurs de température (contrainte due à l'expérimentation).
au secours...ce genre de coefficient n'apporte quasiment aucune information.
Très critique vis-à-vis de ce coefficient! Qu'en est-il de Pearson autrement? Celui-ci ne travaille pas sur les rangs et me donne en effet des résultats assez différents. Je pensais à l'utilisation de ces coefficients car je ne pense pas qu'on ait besoin de sortir la grosse artillerie si l'on sait précisément ce que l'on cherche, en l'occurence à déterminer le sens et la valeur de la corrélation entre 2 variables.
CupOfAppleTea- Nombre de messages : 28
Date d'inscription : 14/12/2012
CupOfAppleTea- Nombre de messages : 28
Date d'inscription : 14/12/2012
Re: régression et non-normalité
par CupOfAppleTea Mer 27 Mar 2013 - 10:37
Je me suis finalement tourné vers la fonction "mblm" du package du même nom qui permet de réaliser des régressions non-paramétriques et qui fournit l'estimateur du paramètre du modèle par la méthode des médianes.
Je voudrais maintenant pouvoir tester statistiquement la valeur de mon estimateur issu du même modèle (variables identiques) appliqué à des pas de temps différents, soient avec des individus différents (cf graphe ci-dessus, points bleus Vs. points rouges).
Existe-t-il une méthode pour faire ça?
Je voudrais maintenant pouvoir tester statistiquement la valeur de mon estimateur issu du même modèle (variables identiques) appliqué à des pas de temps différents, soient avec des individus différents (cf graphe ci-dessus, points bleus Vs. points rouges).
Existe-t-il une méthode pour faire ça?
CupOfAppleTea- Nombre de messages : 28
Date d'inscription : 14/12/2012
Re: régression et non-normalité
par Nik Mer 27 Mar 2013 - 15:46
Les résidus tu veux dire ?visualisation graphique confirme que les données ne suivent pas une loi normale.
Justement si.Je ne pense pas donc que cela pose pb.
Un modèle est différent à partir du moment où les données de la variable expliquée sont différentes et pas selon les variables explicatives rentrées dans le modèle. Donc si tu fais des modèles à des pas de temps différents, alors les y sont différents donc les coefficients ne sont pas comparables.
Dans ton cas tu as clairement une hétéroscédasticité selon la condition expérimentale qui peut donc être rentrée en effet aléatoire dans un modèle mixte. Pour ce qui est de la nature interne du modèle (ANCOVA...) ça dépend effectivement du type de variables explicatives mais c'est très secondaire comme considération car le plus important est de pouvoir interpréter les paramètres.
Le coefficient de Pearson sous des airs de simplicité angélique pose de nombreux présupposés notamment parce qu'il utilise une moyenne des données. Au final, il ne dit pas grand chose car il ne sert qu'à regarder un lien linéaire et pour des données non-hétérogènes. De plus, tu n'as pas tous les outils de la régression pour juger de la pertinence du coefficient. Donc la question n'est pas la lourdeur de l'artillerie mais bien d'adapter les analyses aux données disponibles. Tu es plutôt en train de sortir une canne à pêche pour aller cueillir des champignons
Nik- Nombre de messages : 1606
Date d'inscription : 23/05/2008
Re: régression et non-normalité
par CupOfAppleTea Mer 27 Mar 2013 - 16:10
En effet je voulais parler des résidus, pardon pour l'erreur!
Pour ce qui est des modèles mixtes, j'ai bien peur que le faible nombre d'individus (parfois limité à 2) ne m'empêche d'utiliser les modèles mixtes.
De toute manière, je ne vois pas quel facteur je pourrais rentrer en effet aléatoire.
Finalement, je me penche sur la fonction "gls" du package "nlme". Elle permet en effet de gérer l'hétéroscédasticité des données et reste une méthode paramétrique.
Pour en revenir aux commentaires vis-à-vis de la comparaison des paramètres des régressions je comprends où vous voulez en venir. Je pense que la solution consiste donc simplement à pooler toutes mes données (tous temps confondus) dans une seule régression gls en intégrant l'effet temps. Je saurai ainsi si le temps a un effet ou non. En parallèle je peux également procéder à une regression à chaque pas de temps pour regarder plus finement ce qu'il se passe (points rouges et bleus séparément). Je pense que j'aurai alors toutes les informations dont j'ai besoin:
1°) comparaison points bleus/points rouges
2°) détermination du lien entre mes deux variables à chaque pas de temps
J'espère avoir réussi à troquer ma canne à pêche contre un panier en osier et un couteau bien aiguisé
Pour ce qui est des modèles mixtes, j'ai bien peur que le faible nombre d'individus (parfois limité à 2) ne m'empêche d'utiliser les modèles mixtes.
De toute manière, je ne vois pas quel facteur je pourrais rentrer en effet aléatoire.
Finalement, je me penche sur la fonction "gls" du package "nlme". Elle permet en effet de gérer l'hétéroscédasticité des données et reste une méthode paramétrique.
Pour en revenir aux commentaires vis-à-vis de la comparaison des paramètres des régressions je comprends où vous voulez en venir. Je pense que la solution consiste donc simplement à pooler toutes mes données (tous temps confondus) dans une seule régression gls en intégrant l'effet temps. Je saurai ainsi si le temps a un effet ou non. En parallèle je peux également procéder à une regression à chaque pas de temps pour regarder plus finement ce qu'il se passe (points rouges et bleus séparément). Je pense que j'aurai alors toutes les informations dont j'ai besoin:
1°) comparaison points bleus/points rouges
2°) détermination du lien entre mes deux variables à chaque pas de temps
J'espère avoir réussi à troquer ma canne à pêche contre un panier en osier et un couteau bien aiguisé
CupOfAppleTea- Nombre de messages : 28
Date d'inscription : 14/12/2012
Nik- Nombre de messages : 1606
Date d'inscription : 23/05/2008
» Test de normalité et de corrélation (ou régression)
» normalité
» régression multiple et régression logistique
» Régression Logistique vs Régression Linéaire
» Test de normalité.
» normalité
» régression multiple et régression logistique
» Régression Logistique vs Régression Linéaire
» Test de normalité.
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum|
|
|